
Если в общих словах модель HDBSCAN нам может показать из каких кластеров состоит локальный рынок. Под кластером в нашем примере могут пониматься например квартиры разделенные по цене квадратного метра и количеству комнат, или дома различного класса. Под локальным рынком некая географическая область к которой мы модель применяем. Очевидно что для квартир она сильно меньше чем для загородных домов. Кроме того отмечу что у модели HDBSCAN есть ограничение снизу по количеству обьектов, применять ее к 5-10-30 объектам просто не имеет смысла.
Работа с Гео.
В силу того что модель HDBSCAN требует определенных математических расчетов, мы не можем выполнять ее “на лету” - как только у нас появился новый объект. Поэтому мы должны выделять кластеры заранее, поэтому дать возможность пользователю самостоятельно определять локальную область мы не можем. Поэтому все локальные области мы должны предустановить заранее. Мы используем технологию Uber H3- разбиваем поверхность земли на гексы (равносторонние шестиугольники). Гексы сильно удобнее использовать чем скажем квадраты - мы тем самым минимизируем диагональные аномалии.
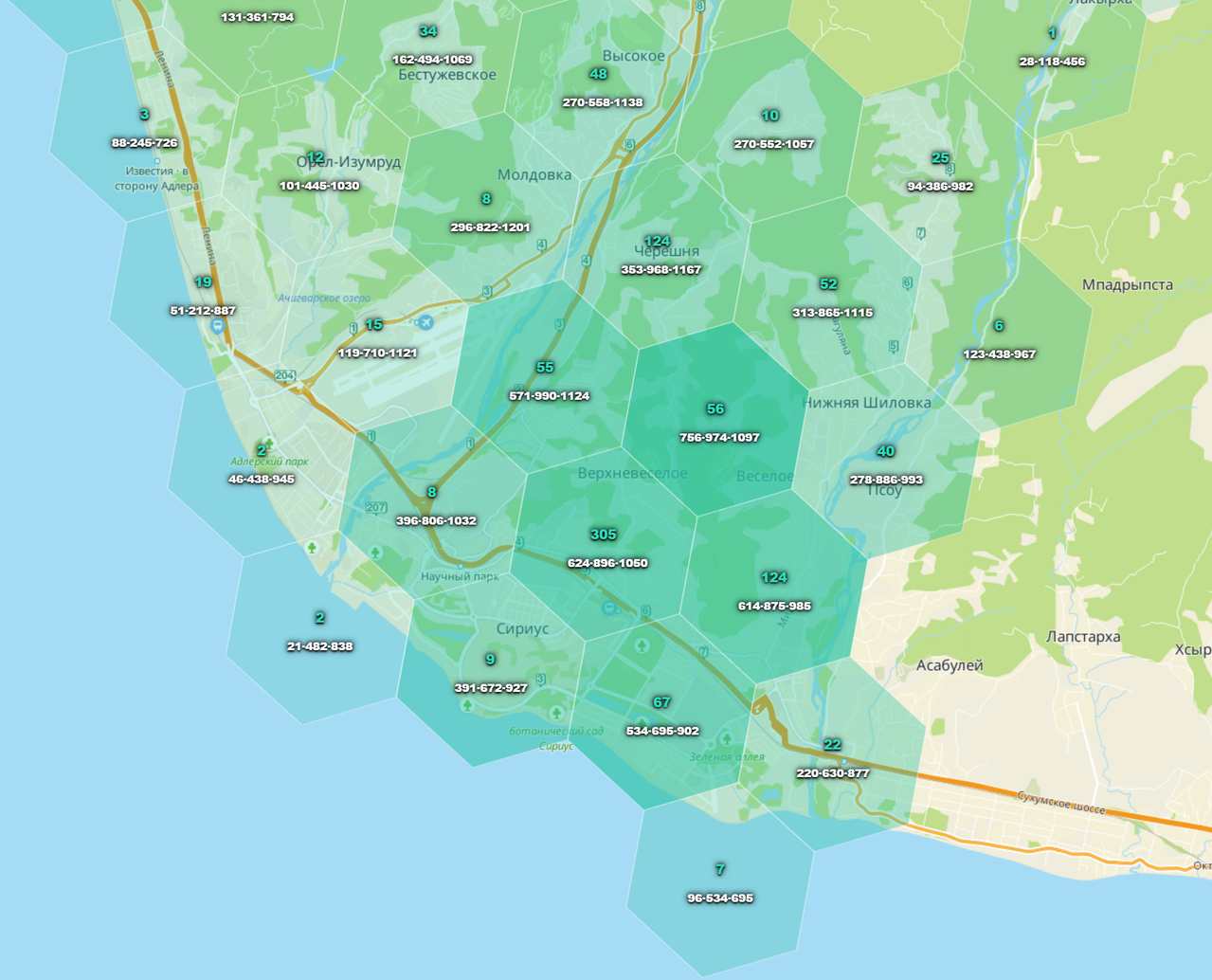 На гексах отражено количество обьектов в самомом гексе и соседних гексах.
На гексах отражено количество обьектов в самомом гексе и соседних гексах.
для квартир: resolution = 9 (мелкий гекс, ~0.17 км по ребру),
для загородки: resolution = 7 (крупнее, ~1.2 км по ребру).
Следующим важным моментом нам нужно определить ко скольки гексам мы применяем модель, дело в том, что в гексе может быть 1 объект. Для этого мы используем идею кольца т.е. на первом этапе смотрим сколько в одном гексе, если объектов недостаточно, берем все соседние если и их недостаточно берем соседей соседних и так далее. В нашей модели мы ограничиваемся 3 шагами обычно этого достаточно. Конечно если у нас дом стоит в лесу то этого не хватает, но в этом случае вообще сложно говорить о кластеризации, да и рынке как таковом.
Целевой объем для HDBSCAN:
- HDBSCAN_RATE_FLAT = 150,
- HDBSCAN_RATE_SUBURBAN = 150
Используя концепцию описанную выше мы получаем, довольно надежную выборку для применения HDBSCAN.
Модель HDBSCAN признаки и их веса.
Применение модели базируется на признаках по которым идет кластеризация для квартир они свои для домов свои, мы выделили следующие признаки и их весовые характеристики (Сегмент/Признак/Вес):
- flat x_geo = 1.0
- flat y_geo = 1.0
- flat log(price_per_m2) =1.5
- flat rooms = 1.0
- flat log(area_m2) = 1.0
- suburban x_geo = 1.0
- suburban y_geo = 1.0
- suburban log(price_per_m2) = 1.5
- suburban house_area_m2= 1.0
- suburban distance_to_city = 0.2
Ключевая интерпретация:
Для цены квадратного метра более правильно использовать не саму цену квадратного метра, а ее логарифм, цена за м² усилена (1.5), расстояние до центра для загородки ослаблено (0.2), геометрия и базовые размерные признаки идут с нейтральным весом 1.0.
Применение модели HDBSCAN (немного математики).
Рассчитываем пространственное приближение в километрах Для объявления i с координатами (lat_i,lon_i), относительно локального центра (lat,lon) рассчитываем:
$$x_i = (\mathrm{lat}_i - \overline{\mathrm{lat}}) \cdot 111$$
$$y_i = (\mathrm{lon}_i - \overline{\mathrm{lon}}) \cdot 111 \cdot \cos(\overline{\mathrm{lat}})$$
Фактически это расстояние каждого объекта до локального центра.
Далее на основе растояний и признаков строим вектора отдельно для квартир и загородной недвижимости:
Квартиры: $$v_i^{\mathrm{flat}} = \left[ x_i,\ y_i,\ \ln(\mathrm{price\_m2}_i),\ \mathrm{rooms}_i,\ \ln(\mathrm{area}_i) \right]$$
Дома: $$v_i^{\mathrm{sub}} = \left[ x_i,\ y_i,\ \ln(\mathrm{price\_m2}_i),\ \mathrm{houseArea}_i,\ \mathrm{distToCity}_i \right]$$
Далее проводим нормализацию и приписываем веса. По каждому признаку рассчитываем: $$z_{ij} = \frac{v_{ij} - \mu_j}{\sigma_j}$$
И применяем вес: $$\tilde{z}_{ij} = w_j \cdot z_{ij}$$
Еще раз отметим, что цена за м² имеет повышенный вес, чтобы рыночная структура сильнее влияла на форму кластеров.
Ну а далее рассчитываем метрику расстояние между нашими векторами:
$$d(a,b) = \sqrt{\sum_j \left(\tilde{z}_{aj} - \tilde{z}_{bj}\right)^2}$$
Это расстояние используется внутри HDBSCAN.
Кроме указанных выше параметров HDBSCAN, модель еще использует ряд параметров динамично рассчитываемых в зависимости от выборки (с эвристическим ограничениями):
$$\mathrm{min\_cluster\_size} = \max\left(5,\ \min\left(15,\ \left\lfloor \frac{n}{10} \right\rfloor\right)\right)$$
Это «зажатая адаптация»:
- floor(n/10) — базовая идея: минимальный кластер ≈ 10% выборки.
- max(5, ...) — не даем опуститься слишком низко на малых выборках.
- min(..., 15) — не даем стать слишком большим на крупных выборках (иначе алгоритм будет слишком грубым).
$$\mathrm{min\_samples} = \max\left(3,\ \min\left(8,\ \left\lfloor \frac{\mathrm{min\_cluster\_size}}{2} \right\rfloor\right)\right)$$
для min_samples та же логика: примерно половина min_cluster_size, но с нижней границей 3 и верхней 8.
То есть модель автоматически подстраивается под объем выборки, но в разумных границах.
HDBSCAN возвращает: метку кластера для каждой точки (-1 = шум), вероятность принадлежности. На уровне кластера мы считаем набор показателей качества/устойчивости (плотность, ценовая когерентность, гео-непрерывность, разнообразие продавцов и т.д.) и строим интегральный индекс.
В результате мы получили несколько кластеров которые у нас характеризуют рынок недвижимости в данной локальной области.
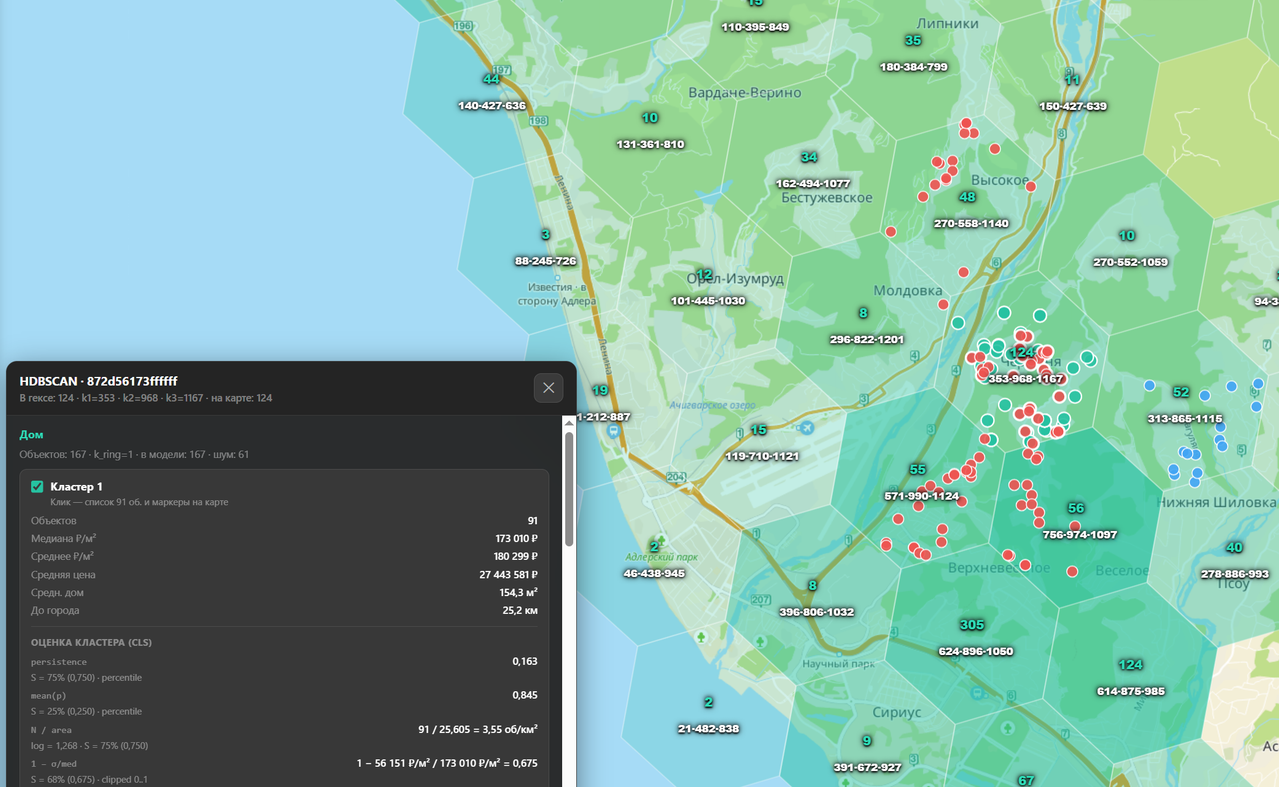 Зеленые отметки это объекты исследуемого гекса, красные и синие это построенные кластеры.
Зеленые отметки это объекты исследуемого гекса, красные и синие это построенные кластеры.
Далее у нас встает два существенных вопроса: Насколько качественно кластеры характеризуют рынок и как определить риск обьекта - то что он не в рынке, а вероятнее всего фейк?
Насколько качественно кластеры характеризуют рынок?
Дело в том что мы изначально работаем на довольно шумном рынке - очень много манипуляций и фейков, есть продавцы связанные с белыми и пушистыми крупными агентствами недвижимости которые размещают фейки в промышленных масштабах. Например, в одном крупном агентстве недвижимости Сочи, было правило - пока сотрудник-агент не разместит с утра 20 объявлений, он не выходит в поля. Естественно далеко не у каждого агента есть соизмеримое количество реальных объявлений. В нашем случае это означает что есть риск того, что какой-то агент пачкой разместит 20 несуществующих объектов в одной локации, которые сами по себе будут образовывать кластер. Очевидно что подобные кластеры не имеют никакого отношения к реальности.
Для этого мы вводим специальную метрику CLS (Cluster Stability) стабильности, качества кластера. Ниже приведены компоненты и расчет нашей метрики CLS:
1. s_stability основана на HDBSCAN - Насколько кластер «устойчив» как структура, а не случайная группа
2. s_membership основано на HDBSCAN - Насколько уверенно объекты принадлежат кластеру
3. s_density основана на log_density
$$\mathrm{density} = \frac{\mathrm{cluster\_size}}{\mathrm{spatial\_area\_km^2}}, \qquad\mathrm{log\_density} = \log(\mathrm{density})$$
Показывает насколько кластер компактный и «плотный»
4. s_price основан на price_coherence (ценовая согласованость):
$$\mathrm{price\_cv} = \frac{\mathrm{std}(\mathrm{price\_per\_m2})}{\mathrm{median}(\mathrm{price\_per\_m2})}, \qquad\mathrm{price\_coherence} = \mathrm{clip}(1 - \mathrm{price\_cv})$$
Показывает насколько цены внутри кластера согласованы
5. s_seller основана на seller_diversity:
$$\mathrm{seller\_diversity} = \frac{\#\mathrm{unique\_sellers}}{\#\mathrm{offers\_in\_cluster}}$$
Отражает риск концентрации продавца (чем выше разнообразие, тем лучше)
6. s_spatial основано на spatial_continuity пространственной неопределенности то то оценка, то оценка, насколько кластер географически цельный: высокий spatial_continuity- объекты собраны компактно и равномерно; низкий spatial_continuity кластер «размазан»/фрагментирован в пространстве. Фактически упрощенно это нормированная гео дисперсия (не буду приводить формулы они очевидны).
7. s_noise основан на noise_ratio:
$$local\_noise\_share = \frac{\#noise}{n}$$, $$local\_noise\_share = \frac{\#noise}{n}$$
По смыслу показывает насколько «чистая» выборка вокруг кластера.
Ну и финальная формула для расчета CLS:
$$CLS = \left( \prod_{i=1}^{7} s_i \right)^{1/7}$$
Значение данного показателя показывает насколько сильно мы доверяем тому или иному кластеру.
Как определить риск обьекта - то что он не в рынке, а вероятнее всего фейк?
Определить в рынке объект или нет можно только сравнив его с этим самым рынком. Рынок при использовании HDBSCAN мы представляем как набор кластеров. Соответственно, если мы доверяем кластерам коэффициент CLS имеет высокое значение, и если объект в рынке, то высока его вероятность попадания хотя бы в один кластер.
Для этой оценки мы используем среднюю дистанцию до объекта x образующих кластер (под дистанцией понимается более широкое понятие чем гео смысл т.к. туда входят другие признаки более детально определение дистанции смотри выше):
$$d_{knn}(x) = \frac{1}{k} \sum_{u \in NN_k(x)} d(x, u)$$
Затем нормируем через P95 - это 95-й перцентиль ( это такое значение, ниже которого находится 95% наблюдений):
$$similarity = clip\left(1 - \frac{d_{knn}}{P95}\right)$$
И наконец то переходим к уровню доверия и риску объявления:
$$confidence = 0.7 \cdot similarity + 0.3 \cdot cls\_norm$$
Далее применяем Percentile-нормализацию:
$$pct = 100 \cdot \frac{below + 0.5 \cdot equal}{N}$$
Рассчитываем риск:
$$offer\_risk = 1 - confidence$$
И отображаем пользователю со следующую шкалу:
- <5 минимальный
- <15 очень низкий
- <30 низкий
- <45 умеренный
- <60 средний
- <75 выше среднего
- <90 высокий
- >=90 критический
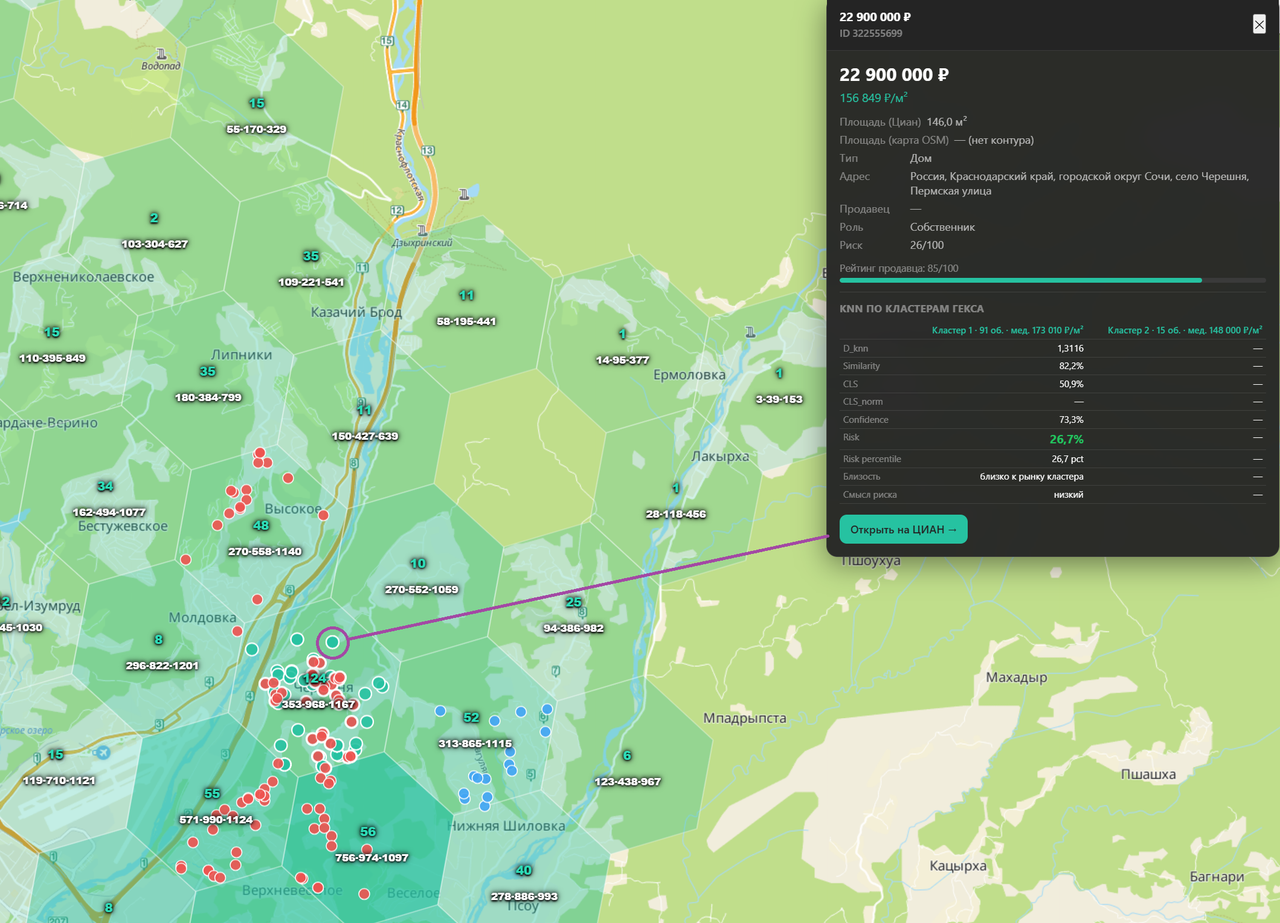
- Как указанно выше модель не работает когда у вас недостаточно объектов в выборке (Пример: дом в лесу, где на много км нет других объектов) минимальный размер для квартир 100 для домов 50 объектов, это подобрано опытным путем. Мы используем для стабильности 150 и там, и там.
- Когда рынок очень не однороден, т.е. представляет смесь рынков отличающихся очень сильно по параметрам и их распределениям, тогда HDBSCAN видит просто шум и не может выделить кластеры. Для этого случая есть другая модель мы приведем ее изложение в следующей статье из цикла Математика Недвижимости.
- Выборка по прежнему (как и в первой статье цикла) не учитывает риск того что автор объявления являются фейкометом - т.е. осознанно искажает рынок. Да, мы проверяем кластеры на концентрацию объявления по автору, но одиночные объявления могут проскакивать в процессе формирования кластера.
Комментарии
Пока нет комментариев.