В предыдущих статьях цикла «Математика недвижимости» мы рассматривали методы выявления подозрительных объявлений на основе локального рынка, HDBSCAN-кластеров и поведенческих характеристик продавцов. Однако существует еще одна сложная ситуация, с которой сталкивается практически любая система автоматической оценки недвижимости.
Проблема заключается в том, что рынок недвижимости редко бывает однородным.
Даже в пределах одного квартала могут одновременно продаваться квартиры в старом фонде и современных жилых комплексах, дома возле водоемов и объекты рядом с оживленными трассами. Если использовать единственную медиану цен для такой территории, можно получить большое количество ложных срабатываний.
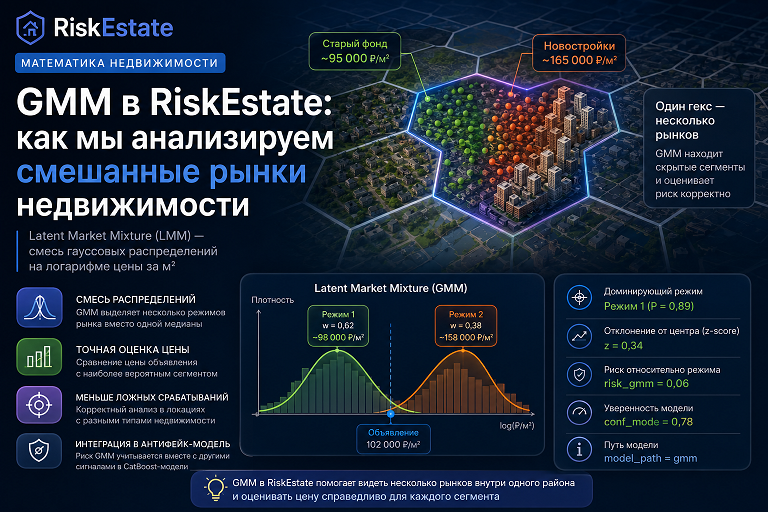
Именно для таких случаев в RiskEstate используется модель Gaussian Mixture Model (GMM), которая в интерфейсе платформы называется Latent Market Mixture (LMM) — латентная смесь рынков.
Почему одной медианы недостаточно?
Большинство классических моделей оценки недвижимости отвечают на вопрос:
«Насколько цена объекта отличается от средней цены в данной локации?»
Такой подход хорошо работает, если рынок внутри рассматриваемой области достаточно однороден.
Представим гексагон H3, в котором одновременно представлены:
- квартиры в панельных домах 1980-х годов стоимостью около 95 000 ₽/м²;
- квартиры в новых жилых комплексах стоимостью около 165 000 ₽/м².
В этом случае медианная цена составит примерно 130 000 ₽/м².
Возникает проблема:
- объект стоимостью 98 000 ₽/м² будет выглядеть подозрительно дешевым относительно медианы;
- объект стоимостью 160 000 ₽/м² — подозрительно дорогим.
При этом оба объекта могут полностью соответствовать своему сегменту рынка.
Именно здесь возникает необходимость разделить рынок на несколько скрытых режимов.
Что такое GMM (Latent Market Mixture)
Gaussian Mixture Model предполагает, что наблюдаемый рынок состоит из нескольких скрытых распределений.
Каждый такой режим характеризуется:
- μ (mu) — типичной ценой сегмента;
- σ (sigma) — разбросом цен внутри сегмента;
- w (weight) — долей сегмента на рынке.
Вместо ответа на вопрос:
«Насколько цена отличается от медианы всего района?»
модель отвечает на более точный вопрос:
«К какому сегменту рынка относится данный объект и насколько его цена отклоняется от типичной цены именно этого сегмента?»
Оценка недвижимости в hex-слое RiskEstate работает каскадно.
Когда запускается GMM
Перед запуском модели RiskEstate оценивает характеристики распределения цен внутри гекса.
Рассчитываются следующие показатели:
- асимметрия распределения (skewness);
- эксцесс (kurtosis);
- пространственный разброс объектов (geo_spread).
На их основе вычисляется триггерный показатель:
$$S = 0.35 \cdot norm(\log(1 + |skew|)) + 0.45 \cdot norm(\log(1 + |kurtosis|)) + 0.20 \cdot geo\_spread$$
GMM запускается только если:
$$S > 0.55$$
Интуитивно это означает следующее:
- высокая асимметрия говорит о наличии длинных ценовых хвостов;
- высокий эксцесс свидетельствует о нескольких ценовых пиках;
- большой пространственный разброс может указывать на существование различных микролокаций.
Если показатель ниже порога, достаточно обычной статистической оценки.
Почему используется логарифм цены
Цены недвижимости имеют тяжелые хвосты распределения.
Разница между дешевым и дорогим объектом может составлять несколько раз.
Поэтому GMM обучается не на исходной цене за квадратный метр, а на логарифме цены:
$$x = \log(price\_per\_m2)$$
Это позволяет значительно улучшить качество моделирования скрытых сегментов рынка.
Выбор количества сегментов
Количество компонент смеси зависит от объема доступных данных.
- N < 50: один режим;
- 50 ≤ N < 200: два режима;
- 200 ≤ N < 1000: три режима;
- N ≥ 1000: максимум три режима.
Минимальное количество объектов для запуска модели:
LaTeX: $$N \geq 3$$
Для обучения используется алгоритм GaussianMixture из библиотеки scikit-learn.
Для каждого сегмента сохраняются:
- вес сегмента (w);
- среднее значение (μ);
- стандартное отклонение (σ);
- типичная цена сегмента:
$$price_{mode} = e^{\mu}$$
Дополнительно рассчитывается критерий качества модели BIC.
Как оценивается конкретное объявление
Предположим, объект имеет цену x.
Сначала вычисляется:
$$x_{log} = \log(x)$$
Для каждого режима рассчитывается вероятность принадлежности объекта.
Шаг 1. Плотность распределения
$$N(x_{log} \mid \mu_k,\sigma_k)$$
Показывает, насколько цена соответствует конкретному режиму.
Шаг 2. Posterior probability
$$P(mode_k|x)=\frac{w_k N(x|\mu_k,\sigma_k)}{\sum_j w_j N(x|\mu_j,\sigma_j)}$$
Это вероятность того, что объект относится именно к данному сегменту рынка.
Шаг 3. Отклонение от центра сегмента
$$z_k = \frac{x_{log}-\mu_k}{\sigma_k}$$
Чем больше отклонение, тем менее типична цена.
Шаг 4. Расчет риска
$$risk_{gmm}=1-e^{-z_k^2/2}$$
Именно этот показатель попадает в систему оценки риска объявления.
Дополнительный показатель уверенности
Кроме риска рассчитывается показатель уверенности модели:
$$conf\_mode = |P_{max} - P_{min}|$$
Интерпретация достаточно проста:
- conf_mode ≈ 0 — объект находится на границе нескольких сегментов;
- conf_mode → 1 — модель уверенно определяет принадлежность объекта.
Это помогает аналитикам правильно интерпретировать полученные результаты.
Пример работы модели
Продемонстрируем применение модели GMM для анализа рынка загородной недвижимости, рядом с Федеральной территорие Сириус (Это рядом с Адлером). Особенностью рынка является очень много фейковых объявлении и рынок сегментирован на два класса- средний и премиум. Вот что дает работа модели:
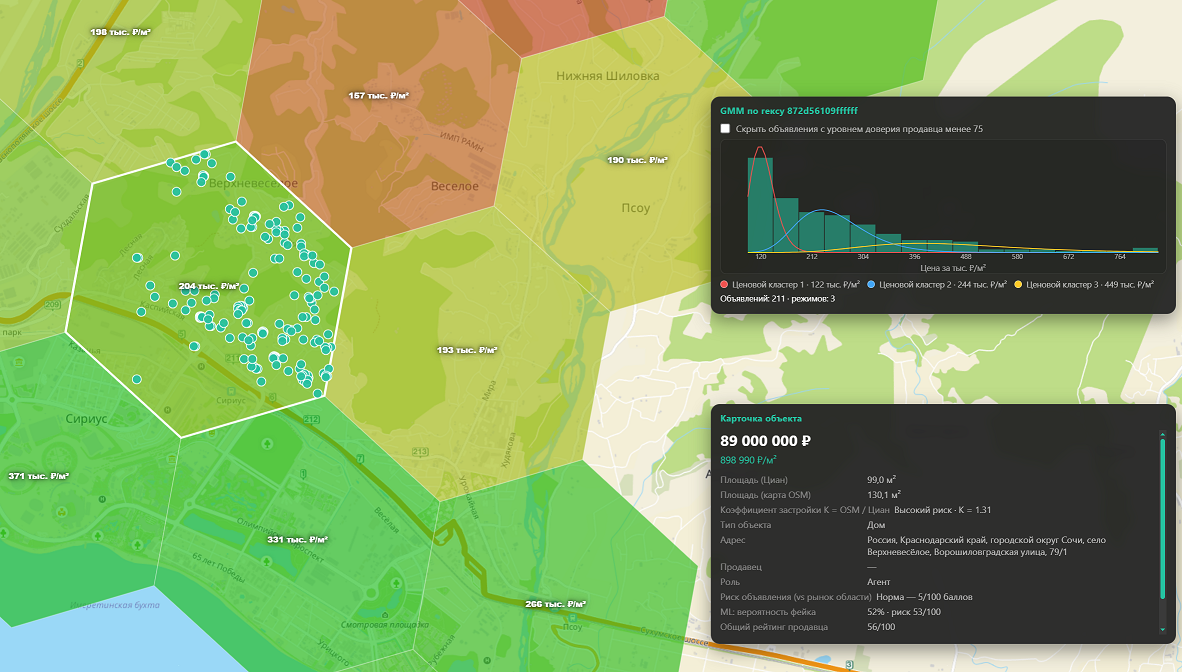 Примененеи модели GMM к кластеру.
Примененеи модели GMM к кластеру.
Ка видим рынок в данном гексе разбился на три режима (кластера):
- Ценовой кластер 1 · 122 тыс. ₽/м²
- Ценовой кластер 2 · 244 тыс. ₽/м²
- Ценовой кластер 3 · 449 тыс. ₽/м
Детальный анализ выборочных объявлении и также применение рейтинга продавца показывает что кластер 1 состоит целиком из фейковых обьявлений, т.е. с помощью этой модели мы смогли отделить шум, от реального рынка, на котором выделяется два ценовых сегмента - дома в среднем по 250 тыс. ₽/м² и 450 тыс. ₽/м. Зная эти параметры и ваш бюджет, основываясь на показаниях этой модели вы сможете самостоятельно и быстро определить что из себя представляет рынок в данной локации для вас.
Ограничения модели
Несмотря на высокую эффективность, GMM имеет ограничения.
- Недостаток данных. При малом количестве объектов модель либо упрощается, либо не используется вовсе.
- Зависимость от качества геоданных. Для анализа используются только объекты с корректной геопривязкой.
- Отсутствие информации о качестве объекта. GMM анализирует исключительно статистику цен. Не учитывает качество ремонта, этажность, видовые характеристики, особенности планировок.
Выводы
GMM в RiskEstate — это инструмент для анализа территорий, где одновременно существуют несколько независимых сегментов недвижимости.
Вместо использования единственной медианы модель пытается определить:
- к какому сегменту относится объект;
- насколько цена отличается от типичной цены этого сегмента;
- насколько уверенно можно сделать такой вывод.
Именно такой подход позволяет значительно снизить количество ложных срабатываний и точнее выявлять действительно подозрительные предложения на сложных и неоднородных рынках недвижимости.
Комментарии
Пока нет комментариев.